 Python is an interpreted high-level programming language for general-purpose programming.
Python is an interpreted high-level programming language for general-purpose programming.
Created by Guido van Rossum and first released in 1991, Python has a design philosophy that emphasizes code readability, notably using significant whitespace.
It provides constructs that enable clear programming on both small and large scales.
1.Pipenv

With Pipenv, you specify all your dependencies in a Pipfile — which is normally built by using commands for adding, removing, or updating dependencies.
The tool can generate a Pipfile.lock file, enabling your builds to be deterministic, helping you avoid those difficult to catch bugs because of some obscure dependency that you didn’t even think you needed.
2.Pytorch

PyTorch builds on and improves the popular Torch framework, especially since it’s Python based — in contrast with Lua.
Given how people have been switching to Python for doing data science in the last couple of years, this is an important step forward to make DL more accessible.
3.Caffe2

The original Caffe framework has been widely used for years, and known for unparalleled performance and battle-tested codebase.
However, recent trends in DL made the framework stagnate in some directions.
Caffe2 is the attempt to bring Caffe to the modern world.
It supports distributed training, deployment (even in mobile platforms), the newest CPUs and CUDA-capable hardware.
While PyTorch may be better for research, Caffe2 is suitable for large scale deployments as seen on Facebook.
4.Pendulum

One of Pendulum’s strength points is that it is a drop-in replacement for Python’s standard datetime class, so you can easily integrate it with your existing code, and leverage its functionalities only when you actually need them.
The authors have put special care to ensure timezones are handled correctly, making every instance timezone-aware and UTC by default.
You will also get an extended timedelta to make datetime arithmetic easier.
5.Dash

Dash, announced this year, is an open source library for building web applications, especially those that make good use of data visualization, in pure Python.
It is built on top of Flask, Plotly.js and React, and provides abstractions that free you from having to learn those frameworks and let you become productive quickly.
The apps are rendered in the browser and will be responsive so they will be usable in mobile devices.
6.PyFlux

PyFlux is an open source library in Python built specifically for working with time series.
The study of time series is a subfield of statistics and econometrics, and the goals can be describing how time series behave (in terms of latent components or features of interest), and also predicting how they will behave the future.
7.Fire

Fire is an open source library that can automatically generate a CLI for any Python project.
The key here is automatically: you almost don’t need to write any code or docstrings to build your CLI! To do the job, you only need to call a Fire method and pass it whatever you want turned into a CLI: a function, an object, a class, a dictionary, or even pass no arguments at all (which will turn your entire code into a CLI).
8.imbalanced-learn
In an ideal world, we would have perfectly balanced datasets and we would all train models and be happy.
Unfortunately, the real world is not like that, and certain tasks favor very imbalanced data.
For example, when predicting fraud in credit card transactions, you would expect that the vast majority of the transactions (+99.9%?) are actually legit.
Training ML algorithms naively will lead to dismal performance, so extra care is needed when working with these types of datasets.
Fortunately, this is a studied research problem and a variety of techniques exist.
Imbalanced-learn is a Python package which offers implementations of some of those techniques, to make your life much easier.
It is compatible with scikit-learn and is part of scikit-learn-contrib projects.
9.Flashtext
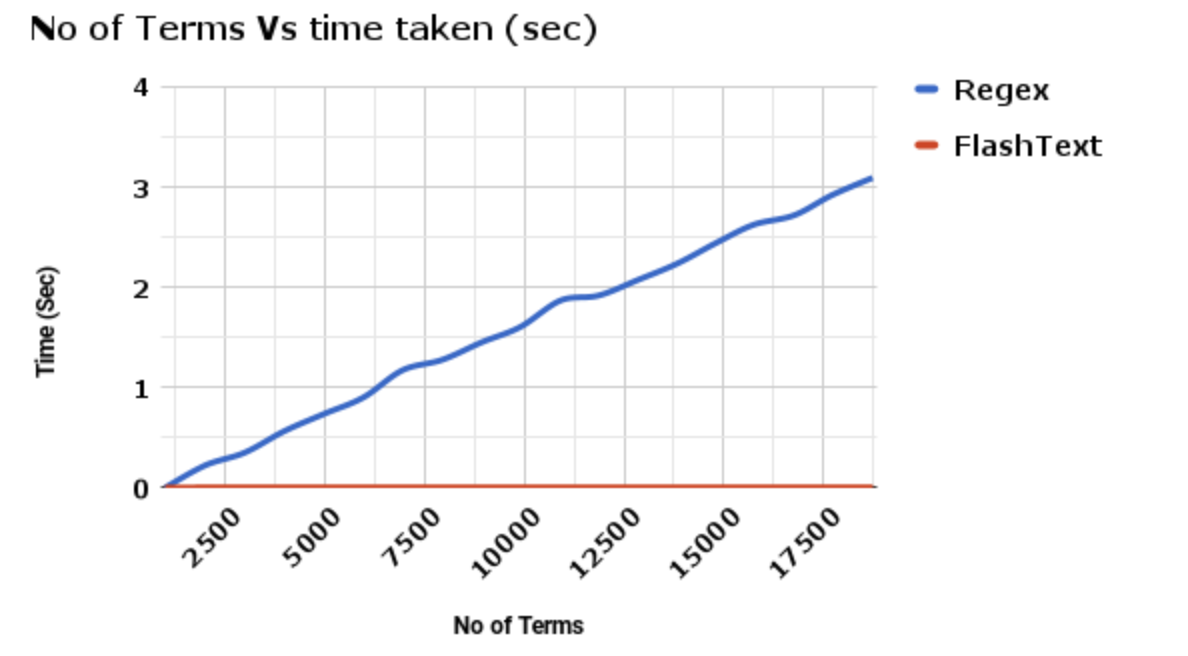
FlashText is a better alternative just for this purpose.
In the author’s initial benchmark, it improved the runtime of the entire operation by a huge margin: from 5 days to 15 minutes.
The beauty of FlashText is that the runtime is the same no matter how many search terms you have, in contrast with regexp in which the runtime will increase almost linearly with the number of terms.
10.Luminoth

Images are everywhere nowadays and understanding their content can be critical for several applications.
Thankfully, image processing techniques have advanced a lot, fueled by the advancements in DL.
Luminoth is an open source Python toolkit for computer vision, built using TensorFlow and Sonnet.
Currently, it out-of-the-box supports object detection in the form of a model called Faster R-CNN.